




はじめに
人工知能の進化し続ける風景の中で、新しいプレーヤーが登場しました:Graph RAG。最近、Microsoftによってオープンソース化されたGraph RAGは、ナレッジグラフの力を情報強化生成(RAG)と組み合わせ、従来のRAGシステムの能力を向上させることを約束しています。このブログ投稿では、Graph RAGの機能について深く掘り下げ、信頼できるソースからのチャールズ・ディケンズのA Christmas Carolのコピーを使って実験します。
従来のRAGの理解
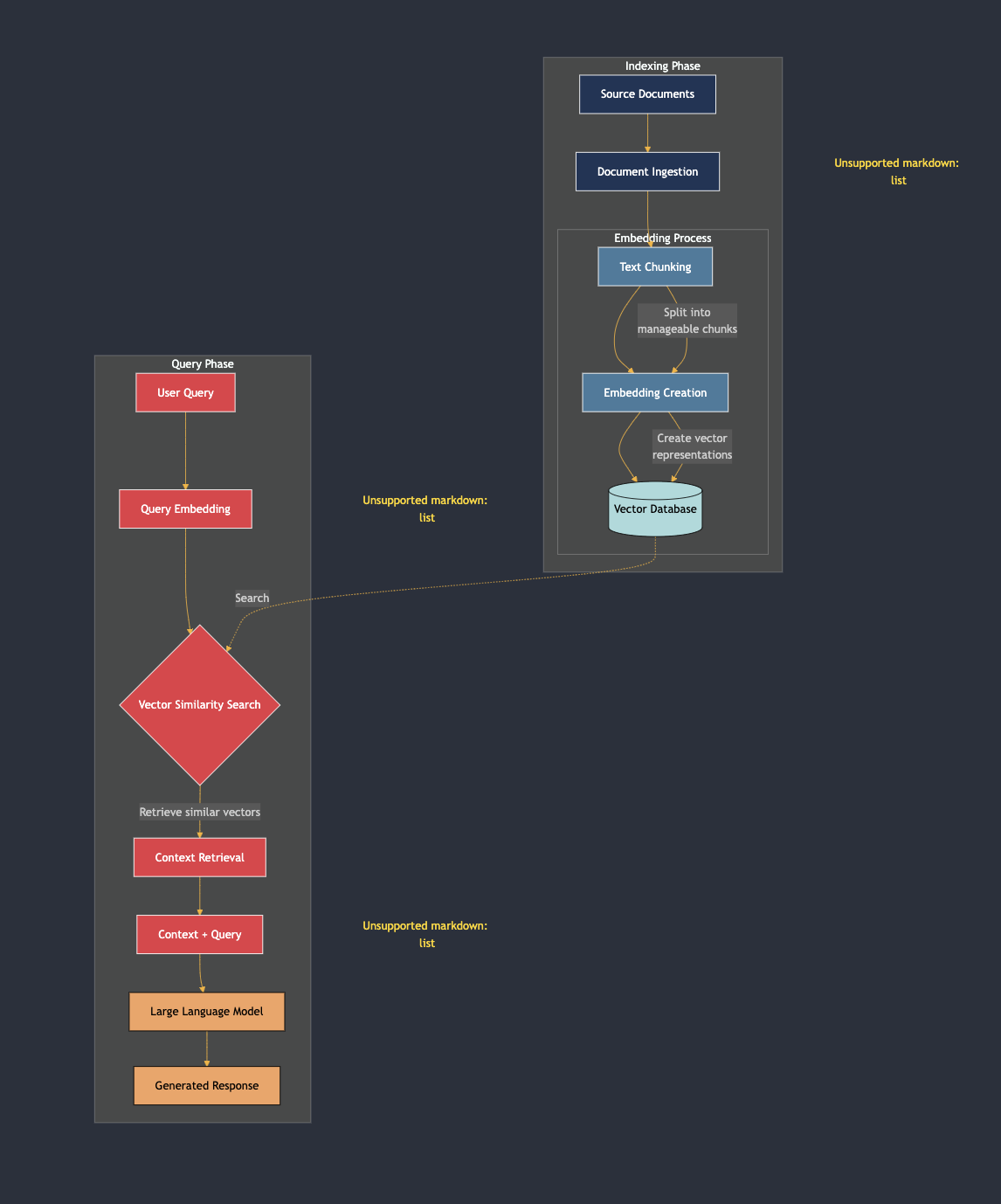
Graph RAGの進展を探る前に、従来のRAGアプローチを理解することが重要です。RAGシステムは、大規模なコーパスから関連する文書を取得し、文脈に適した応答を生成します。このプロセスは通常、2つの主要なフェーズで構成されています:
- インデックスフェーズ:
- 元の文書は、チャンク戦略を使用して小さなチャンクに分割されます。
- 各チャンクはベクトルに変換され、ベクトルデータベースに保存され、ナレッジベースが作成されます。
- クエリフェーズ:
- ユーザーがクエリを送信すると、クエリの埋め込みが計算されます。
- ベクトルデータベース内で類似検索が行われ、最も関連性の高いチャンクが取得されます。
- これらのチャンクは、大規模言語モデル(LLM)に供給され、最終的な応答が生成されます。
従来のRAGの制限
従来のRAGシステムは革命的ですが、顕著な制限があります:
- 限られた文脈理解: データのニュアンスを見落とし、文書の全体像が欠けている可能性があります。
- スケーラビリティの問題: コーパスが成長するにつれて、取得プロセスが効率的でなくなる可能性があります。
- 複雑さ: 外部の知識ソースを意味のある方法で統合することは煩雑です。
Graph RAGの紹介
Graph RAGは、ナレッジグラフを活用することでこれらの制限に対処することを目指しています。Microsoftはコードと共に、「ローカルからグローバルへ:クエリ中心の要約に対するGraph RAGアプローチ」という包括的な技術報告書を発表しました。
Graph RAGの技術的詳細
Graph RAGは、インデックスとクエリの2つの主要なフェーズで構成されています。
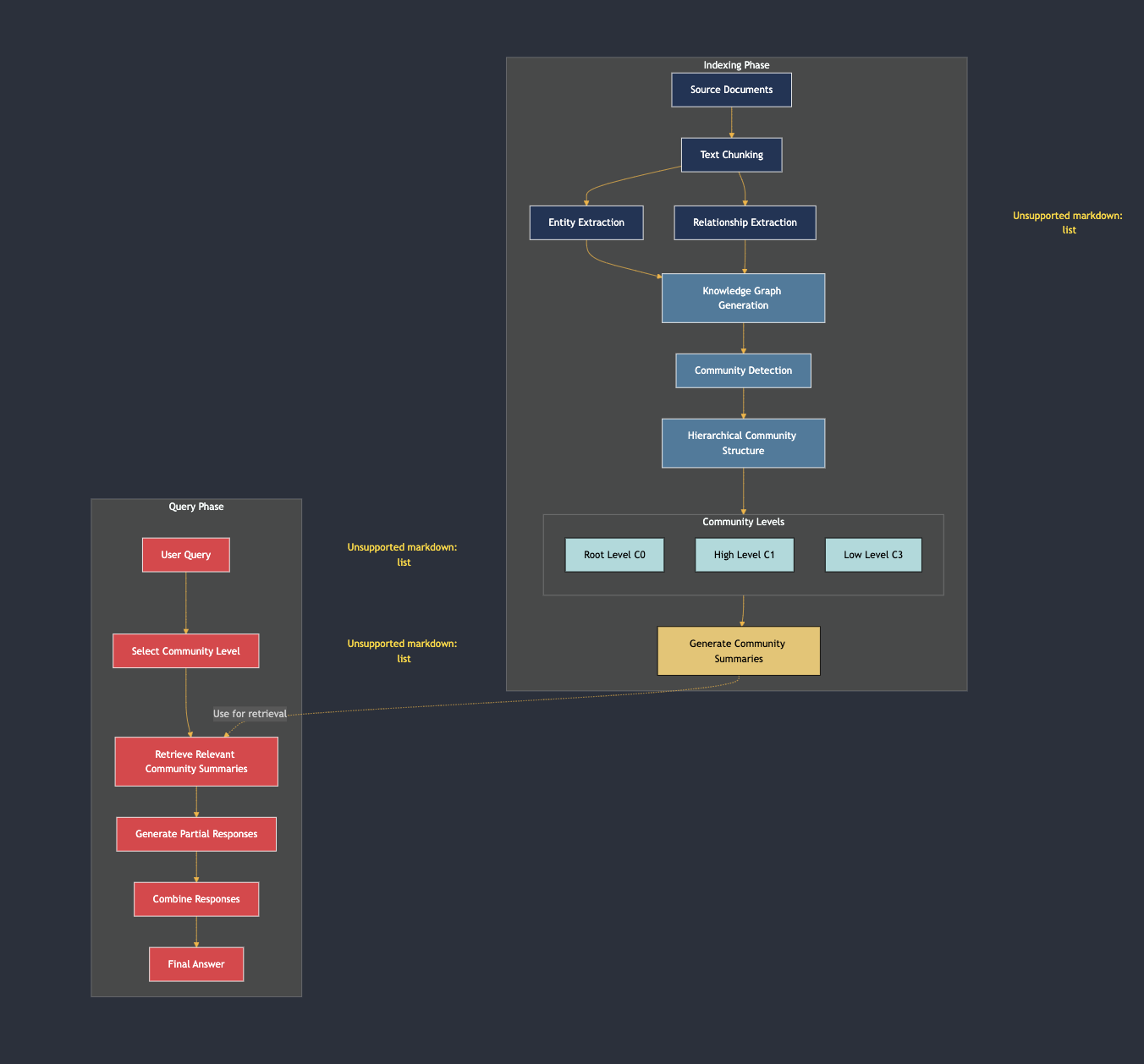
- インデックスフェーズ:
- 文書は、従来のRAGと同様にサブ文書に処理されます。
- Graph RAGは、チャンク間のエンティティ(人、場所、企業)とその関係を特定します。
- ナレッジグラフが作成され、エンティティ間の関係を表すノードのセットになります。
- 関連するエンティティのコミュニティが形成され、各コミュニティの要約が生成されます。
- クエリフェーズ:
- ユーザーがクエリを送信すると、Graph RAGは必要な詳細に基づいて適切なコミュニティレベルを選択します。
- これらのコミュニティから要約を取得して、最終的で一貫した応答を生成します。
この方法は文脈理解を向上させ、従来のRAGの主要な欠点の1つに対処します。
Graph RAGでのクエリ実行
Graph RAGの力を示すために、チャールズ・ディケンズの古典文学作品A Christmas Carolがどのように処理されるかを見てみましょう。クエリを実行するための基本的な手順は次のとおりです:
- Python環境をセットアップし、Graph RAGをインストールします:
pip install graphrag - 「A Christmas Carol」のコピーを取得します:
curl https://www.gutenberg.org/cache/epub/24022/pg24022.txt > ./ragtest/input/book.txt - 作業スペースの変数をセットアップします:
python -m graphrag.index --init --root ./ragtest - Neo4jインスタンスを設定し、要素をNeo4jデータベースに追加します。
- Neo4jデータベース内の関連エンティティのコミュニティを見つけるためにクエリを実行します:
MATCH (d: __Document__) WITH d LIMIT 1 MATCH path= (d)<-[:PART_OF]-(:__Chunk__) - [:HAS_ENTITY]->()-[:RELATED] - () - [:IN_COMMUNITY] ->() return path LIMIT 100
このクエリは、ストーリーのエンティティ間の関係を視覚化したナレッジグラフを生成します:
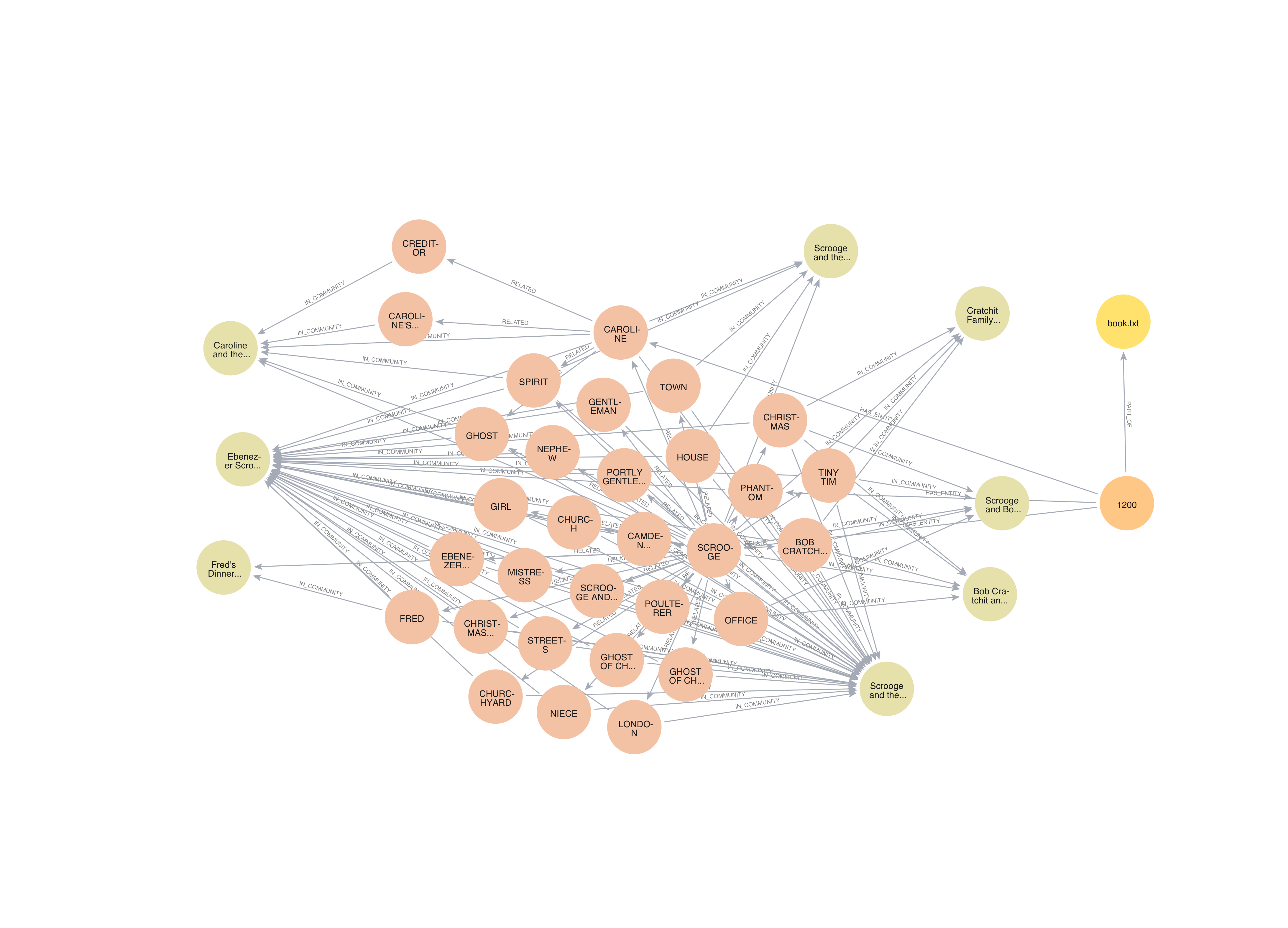
ナレッジグラフの説明:
- エンティティ: 円形のノードで表され、キャラクター(例:「フレッド」、「ボブ・クラチット」)、場所(例:「ロンドン」)、概念(例:「クリスマス」)、およびソース資料(「book.txt」)を含みます。
- 関係: エンティティを接続する矢印として表示され、「IS_COMMUNITY」、「RELATED」、「IS_PART」などがあります。
- コミュニティ: 緊密に関連するエンティティのグループであり、異なる色(例:メインストーリーのオレンジノード、ソース資料の黄色)で表されます。
Graph RAGの実行:『A Christmas Carol』の分析
Graph RAGの力を示すために、A Christmas Carolのテーマをどのように分析するかを見てみましょう:
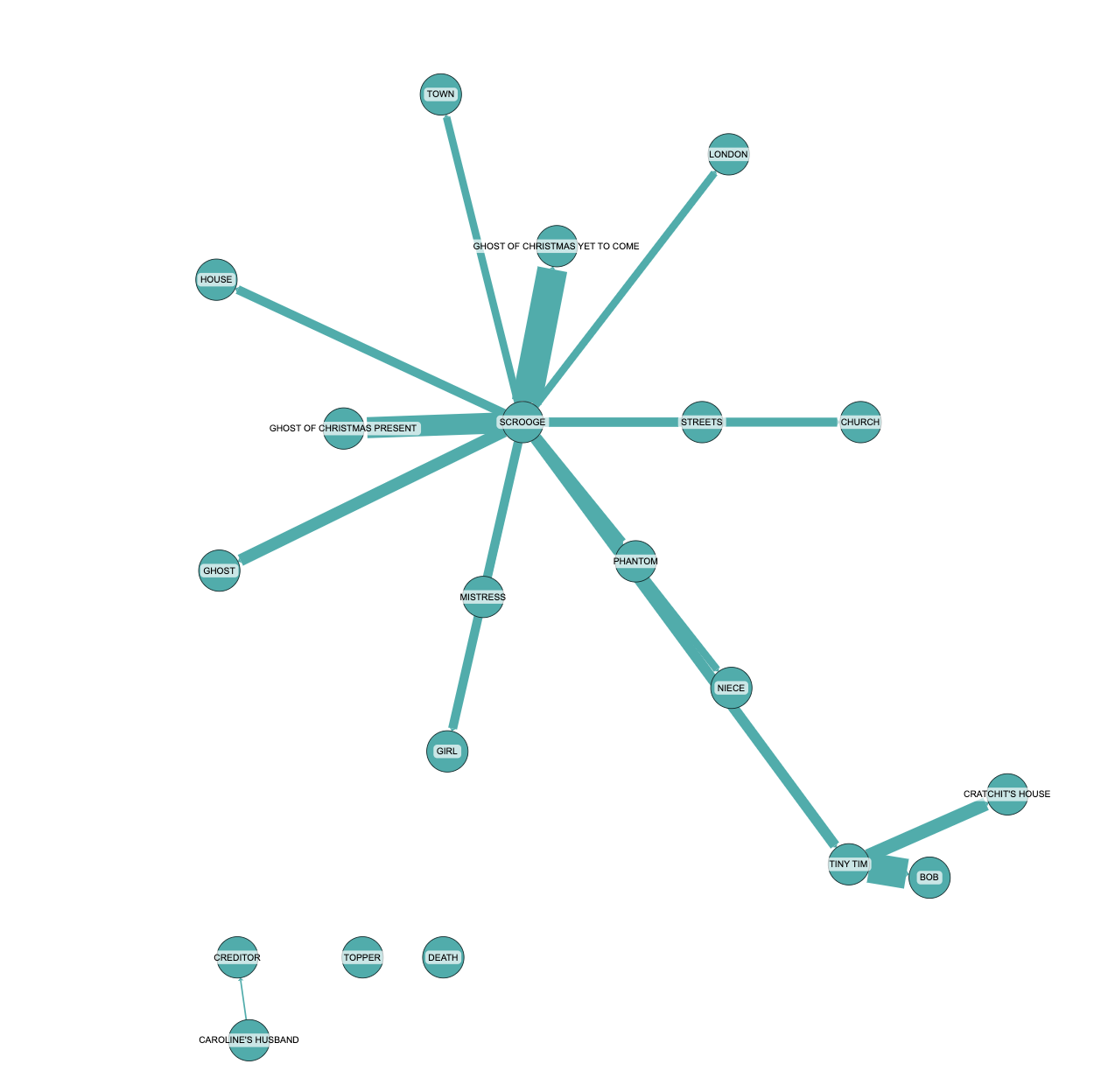
Graph RAGは、いくつかの主要なテーマを特定します:
- 変革と贖罪: スクルージのけちけちから寛大さへの旅。
- 寛大さの影響: スクルージの変化が周囲の人々、特にクラチット家にどのように影響を与えるか。
- 家族と社会的絆の重要性: スクルージの家族やコミュニティへの再統合。
- 孤立の結果: 意義のあるつながりがないことの悪影響。
- クリスマスの象徴性: 変化と再生の触媒として。
- 超自然的な役割: 精霊がスクルージの変革を導く方法。
『A Christmas Carol』のテーマに関するクエリの応答:
エベネザー・スクルージの物語は、変革、寛大さ、家族の重要性、孤立の結果、クリスマスの象徴性、超自然の役割を探求するテーマに満ちています。これらのテーマは物語の中で巧みに織り交ぜられており、贖罪の魅力的な物語と、親切やコミュニティの持続的な影響を提供しています。
この分析は、Graph RAGの複雑な物語に対する包括的かつ文脈に基づく理解を提供する能力を示しています。
課題と制限
Graph RAGは文脈理解とクエリ処理の大幅な改善を提供しますが、計算コストが高くなります。たとえば、Graph RAGを通じて『A Christmas Carol』を処理した結果、100万トークン以上が処理され、単一の実行に約2ドルのコストがかかりました。これは、特に大規模なデータセットに対して、従来のRAGシステムよりもかなり高価です。
結論
Graph RAGは、ナレッジグラフを通じて情報取得システムを強化する革新的なアプローチを表しています。従来のRAGの制限に対処し、より豊かな文脈理解を提供する一方で、コストの影響を慎重に考慮する必要があります。この技術を採用する組織が増える中、さまざまな実装を比較することで、特定のアプリケーションに最適な選択を見つけるのに役立つかもしれません。
特定の問題に応じて、どのタイプのモデルを選択するか(ローカルモデルを含む)を考慮できます。設定.yamlファイルでは、モデルを選択するために設定を調整できます。Graph RAGのセットアップや実験で問題が発生した場合は、私たちのRnDチームにお問い合わせください。







