




名刺管理の現状と課題を一見!
「いただいた名刺がどこにあるのか分からず、連絡が遅れてしまった…」
「山積みの名刺を前に、整理する時間も気力もない…」
「必要な名刺を探して、会議中に焦ったことがある…」
こんなシーン、思い当たりませんか?
名刺管理を効率化することで、商談や顧客対応のスムーズさが向上し、業績の向上にもつながります。この記事では、Dify、生成AI、Notion、Slackを組み合わせた、無料で始められる名刺管理ワークフローを提案いたします。
ぜひお試しください!
名刺管理の現状とOCR活用による改善策!
現在、多くの企業では名刺管理が手作業で行われており、効率的な運用が難しい状況です。以下は、一般的に使用されているフローです。
従来の名刺管理フロー
① 名刺情報の受け取り
② 未加工情報の手作業入力
③ 入力した情報を整理し、Excelや共有フォルダに保存
OCRを活用した改善点
① 情報の自動抽出
・Dify を活用し、名刺情報を迅速かつ正確に抽出
② データの効率的保存
・抽出した情報をNotionまたはAWS RDSに効率的に保存
③ シームレスなシステム連携
・Slackを通じてシステムと簡単に連携。将来的にアプリやウェブにも対応可能
④ コスト効率の良い処理
・処理ロジックはAWS Lambdaを利用して、コスト効率よく実行
⑤ 柔軟な項目調整
・抽出項目はNotionで簡単に設定・調整でき、柔軟に対応可能
名刺管理システムのご紹介
上記の改善点を踏まえ、OCRを活用した名刺管理システムの詳細な機能をご説明いたします。
まずは、主要な機能は以下の通りです。
- 名刺データの受信
- OCR(Dify)でデータを読み取る
- データをシステムに登録
- 決まった時間内でデータを取得
【事前準備】
開始する前に、DifyのOCRを使用した名刺データ抽出用テンプレートをダウンロードしてください。
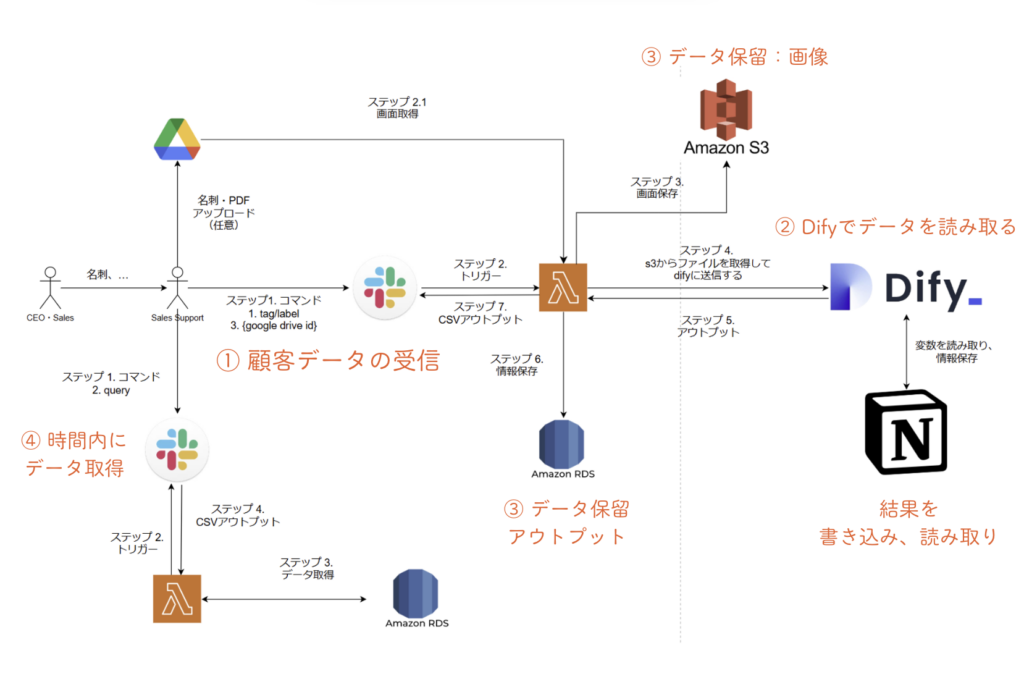
名刺データを受け取り、システムに取り込む
CEOやSalesから受け取った名刺情報をシステムに取り込みます。主な流れは以下の通りです:
- 名刺データをSlack経由で受け取る
- 受け取ったファイルをGoogle DriveまたはSlackからS3に保存
- LambdaがS3からファイルを取得し、Difyに送信
- 名刺情報を抽出し、RDSデータベースに記録
- CSV形式で情報をSlackに返送
データ活用の可能性を広げる!
処理済みデータをデータベースに保存することで、さらなる機能の展開が可能です。今回は以下の2つのアプローチをご紹介します。
① Notion 対応版
・「決まった時間内でのデータ取得機能」をNotion公開のみをサポートする形で実装した形式。
② SlackとGoogle Drive 活用版
・SlackとGoogle Driveを組み合わせた形式(内部利用向けバージョン)。
ツールの準備
① Dify AI
- 概要:Difyは、AIアプリケーションの作成と管理を簡単に行えるプラットフォームです。
- 準備:クラウド版 Dify のアカウントを作成してください。
② Notion
- 概要:Notionは、柔軟で直感的な情報管理ツールです。
- 準備:Notionのアカウントを作成してください。
Notionの準備
■ インテグレーション作成とAPIシークレットキーの取得
① 以下のリンクにアクセスします
・Notionのインテグレーション(外部ツールやサービスとの連携)https://www.notion.so/profile/integrations
② 画面右上の「新しいインテグレーション」(New Integration)をクリックします
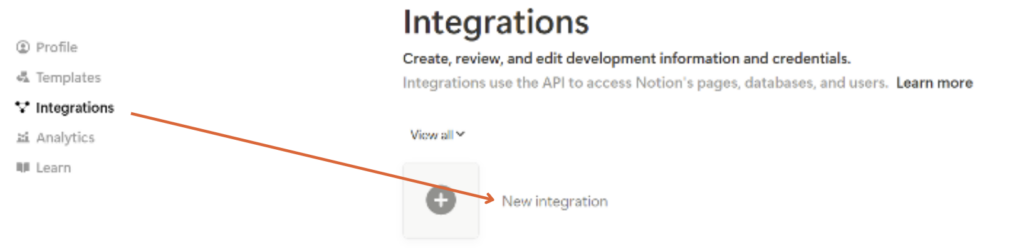
③「関連ワークスペース」を選び、「種類」を「内部」に設定後、「保存」をクリックします
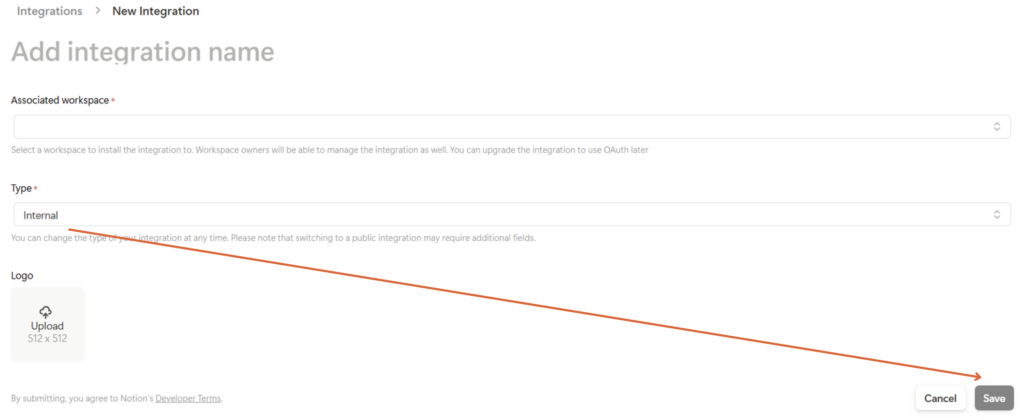
※ 内部 Internal:インテグレーションは自分のアカウント内でのみ利用できます
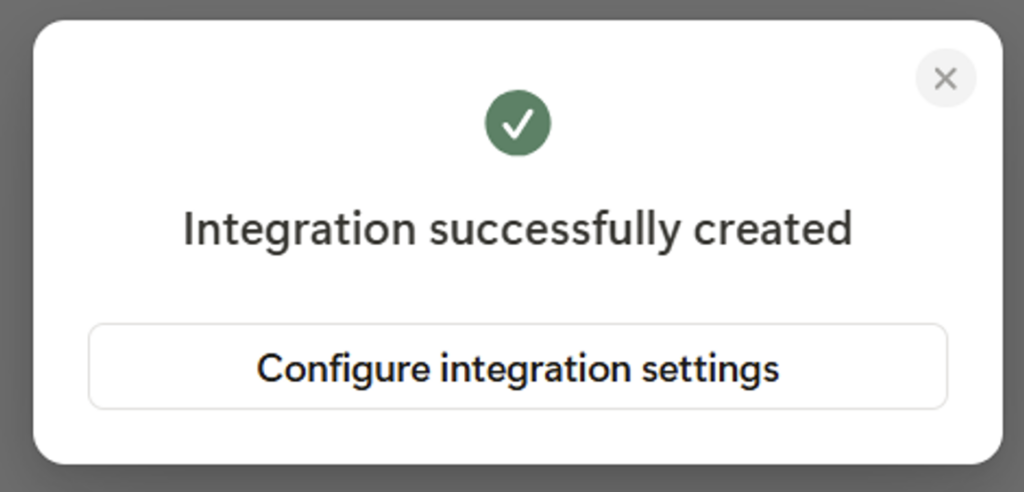
④ 新しい画面が表示されたら、「表示」(Show)をクリックしてAPIシークレットキーを表示します
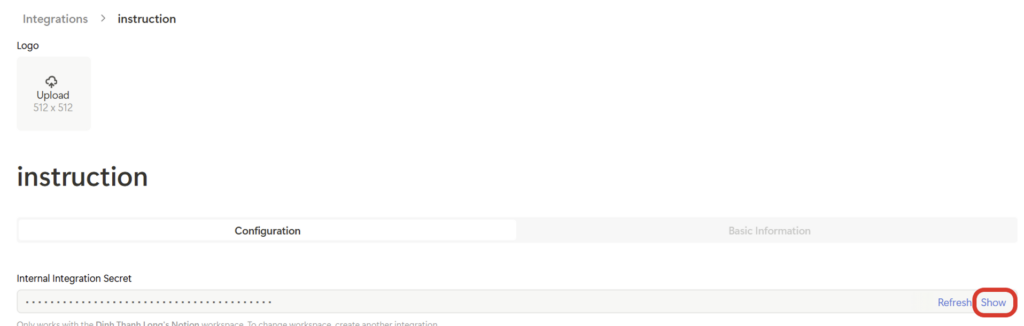
このキーはDifyとNotionを接続するために必要ですので、安全に保存してください。
■ 名刺管理用データベースの作成
① 作成したNotionワークスペースに戻り、「ページを追加」をクリックします
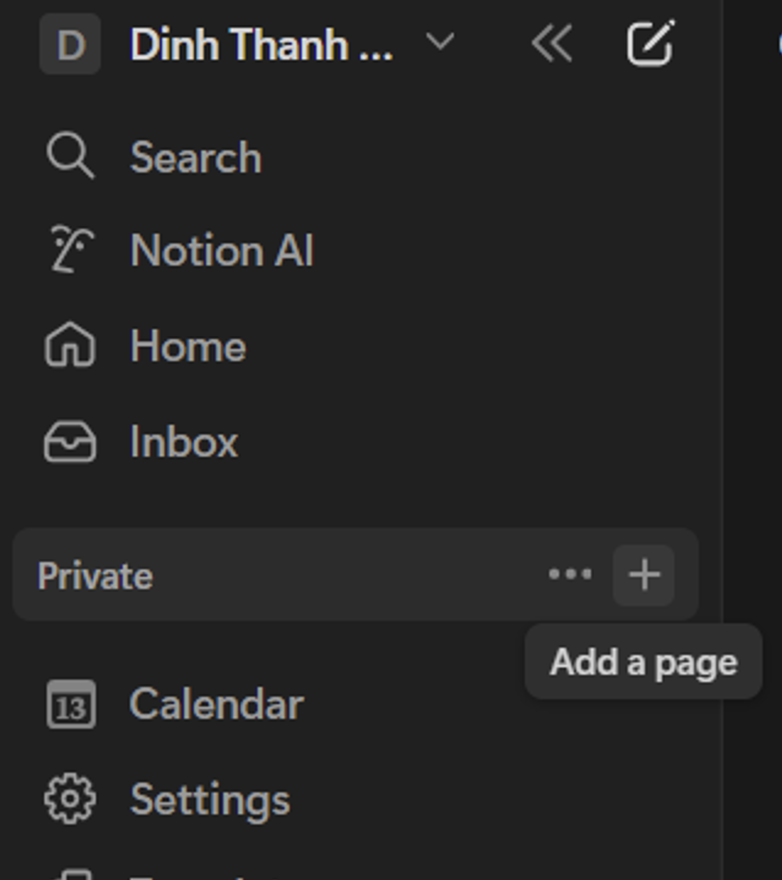
② 「テーブル」を選択して、新しいテーブルを作成します

必要なカラム(例: テキスト、URL、メール)を追加します。他のフィールドが必要な場合はDifyの設定セクションを参照してください
③ 作成したテーブルで「ビューのリンクをコピー」(Copy link)をクリックします
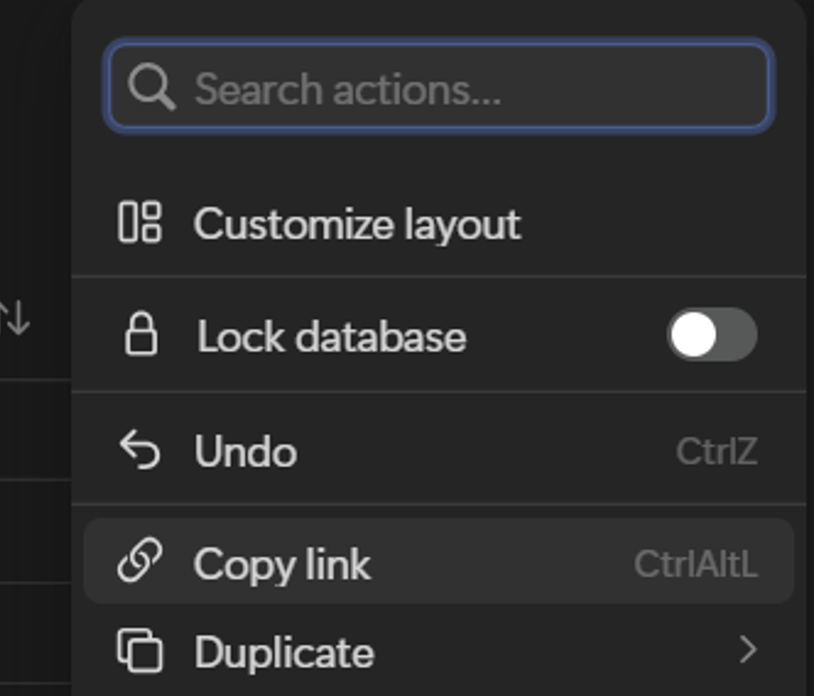
コピーしたリンクの「DATABASE_ID」を控えておいてください。後でDifyとの接続に使用します。
リンクの形式例: https://www.notion.so/<DATABASE_ID>?v=XXX&pvs=4■ Notionの接続設定
「接続先」(Connections)をクリックします
先ほど作成したインテグレーション(Dify Card)を選んでください。
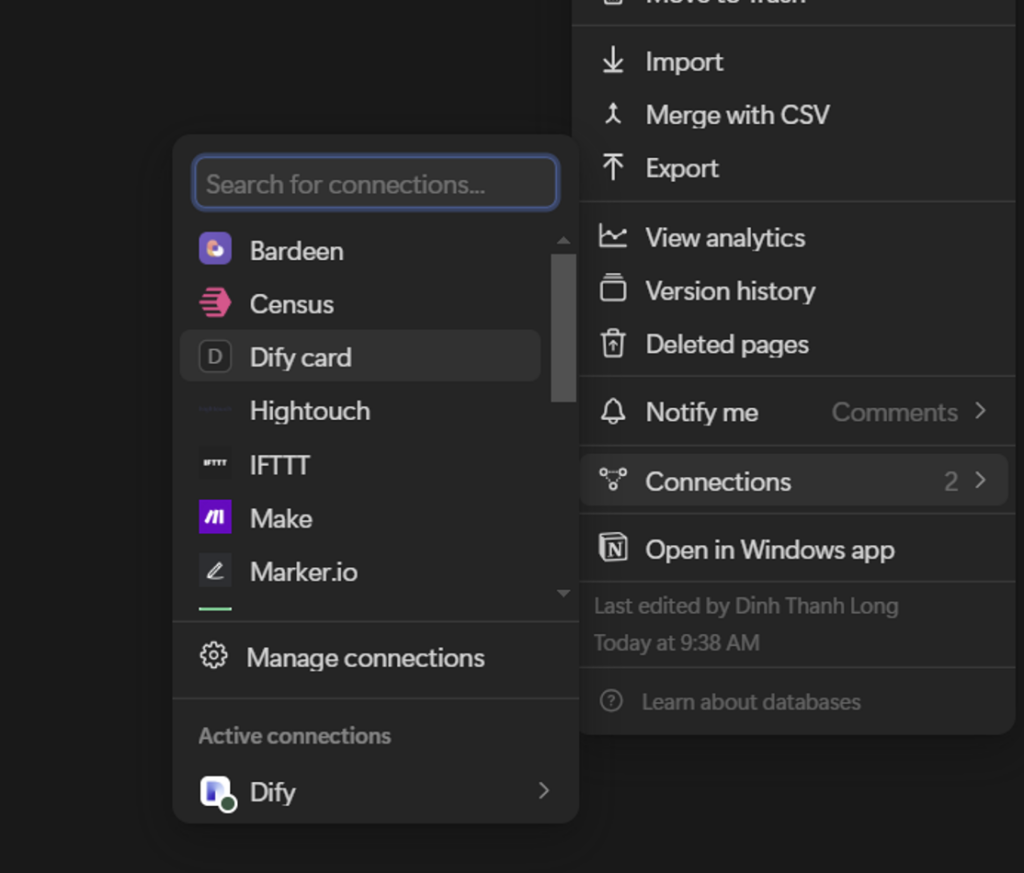
これでNotionの設定が完了しました!次はDify AIの設定に進みます。
Dify AIの準備
■ Dify ワークフローのセットアップ
概要:Difyを活用したワークフローのテンプレートや設定ファイルが含まれたリソースです。
目的:ワークフロー構築・運用のガイドラインとして、テンプレートを活用して効率的にセットアップできます。
アクション:以下のリンクからファイルをダウンロードしてご利用ください。
この準備を完了すれば、ワークフローをスムーズに進めることができます。
■ ワークフローの初期設定
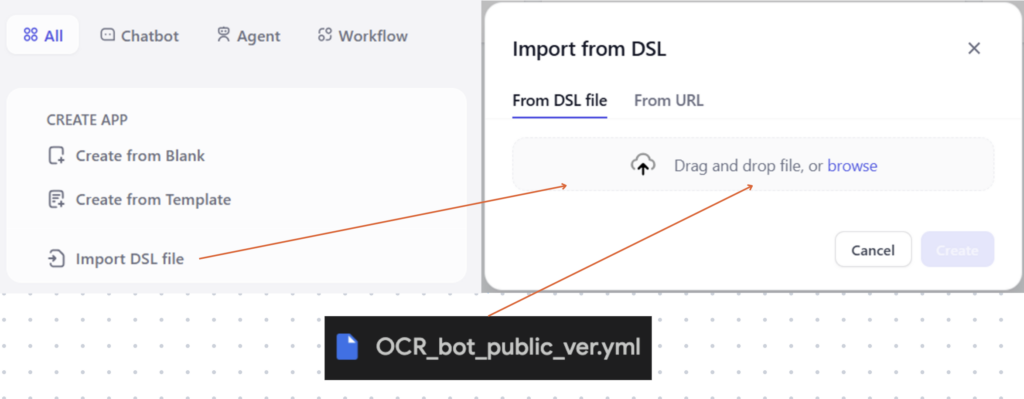
① Difyでワークフローをインポート
ダウンロードしたファイルをDifyで開き、「DSLファイルをインポート」を選択して、ワークフロー設定ファイルをインポートしてください。
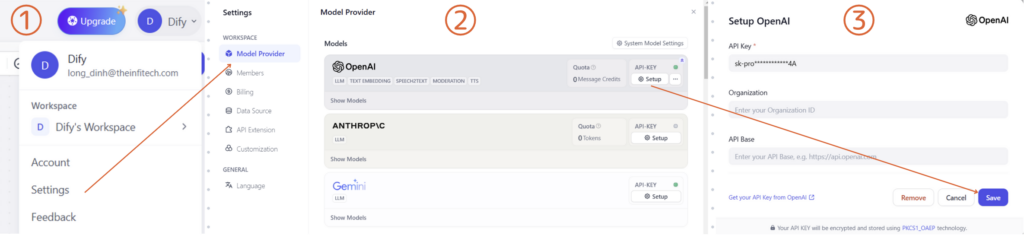
② LLM APIキーの設定
Difyの右上メニューから「設定」(Settings)を選び、「モデルプロバイダー」(Model Provider)に進んで、OpenAIのセットアップを行ってください。他のLLMを使用することも可能です。
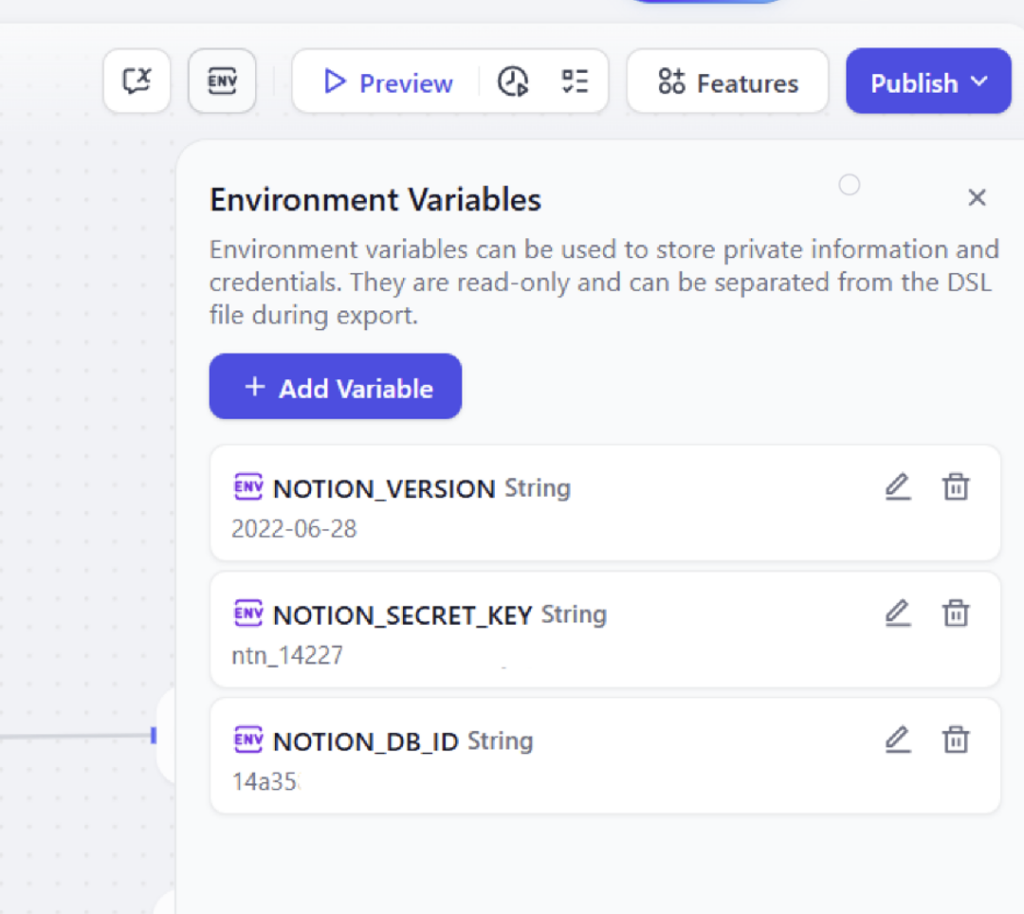
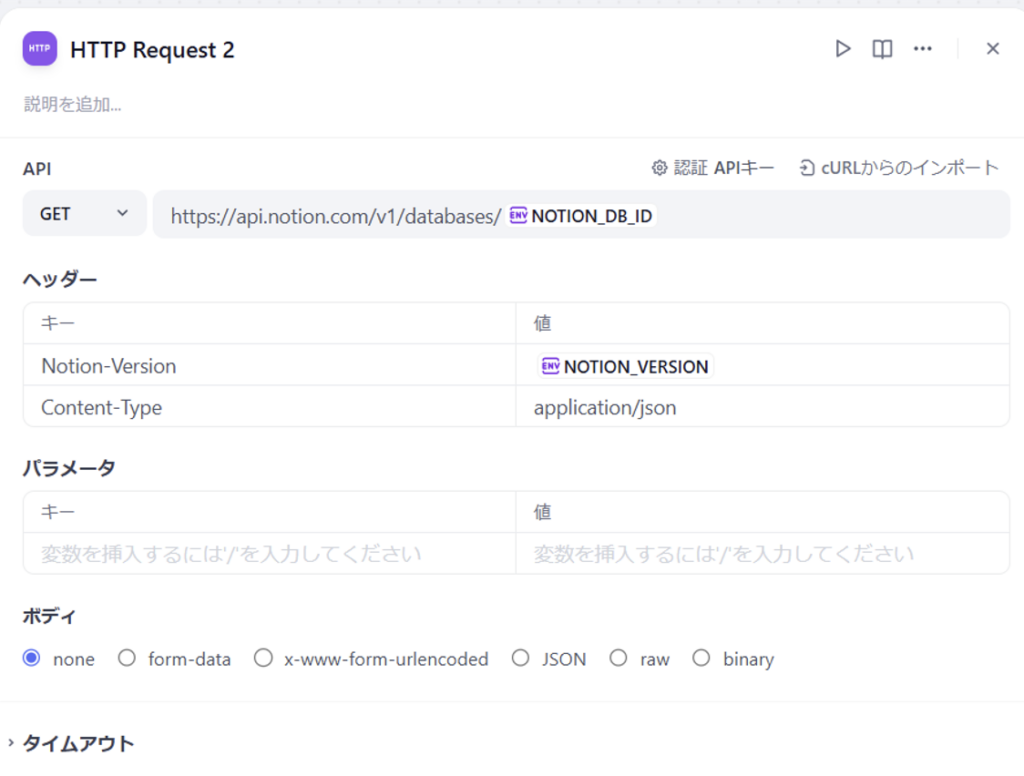
③ 環境変数の設定
- NOTION_DB_ID: 作成した名刺管理「DATABASE_ID」
- NOTION_SECRET_KEY: Notionで設定したAPIのシークレットキー
- NOTION_VERSION: 2022-06-28
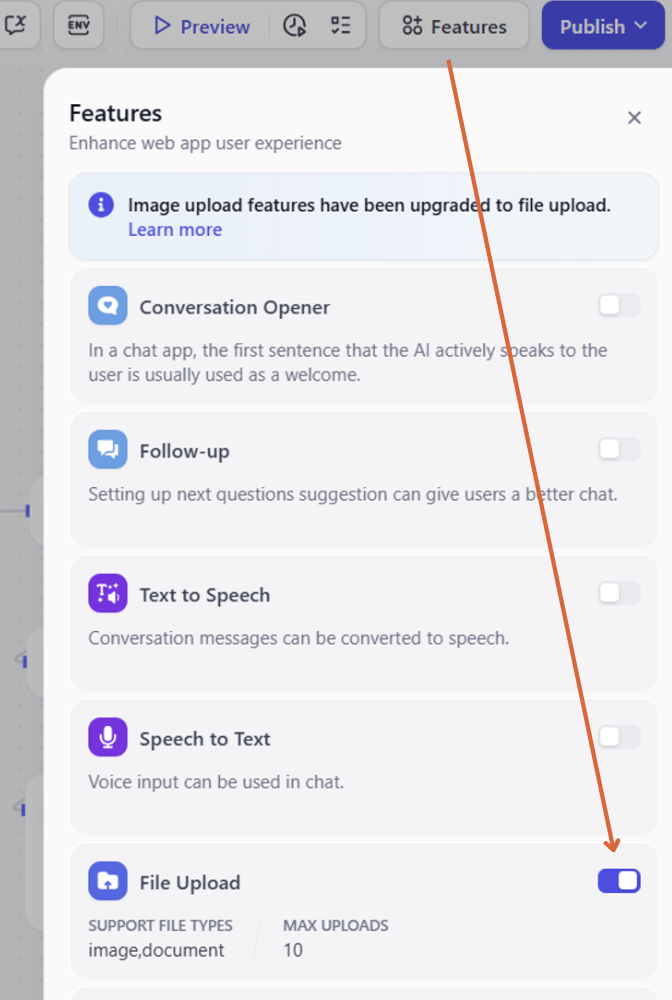
④ 機能設定
ワークフローで名刺の画像をアップロードするには、「機能」(Features)セクションで「画像アップロード」(File Upload)をオンにしてください。
⑤ ワークフロー公開 → 埋め込むコンポーネント
すべてのステップが完了したら、「アップデート」(Update)をクリックしてワークフローを公開します。公開後、「ウェブサイトに埋め込む」(Embed on Website)をクリックします。表示されたiframeコードをコピーしてください。
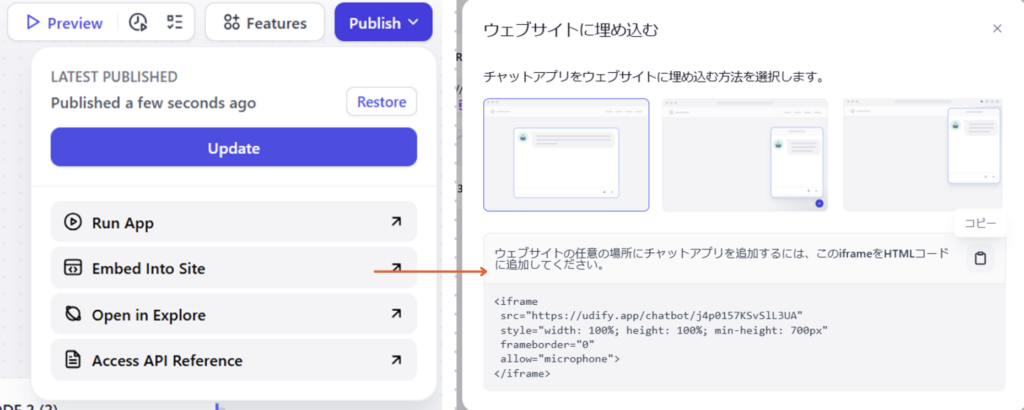
⑥ 埋め込むコンポーネントの導入
Notionに戻り、結果管理の新しいページを作成します。
- ページのコンテンツ部分に「/embed」と入力し、コピーしたiframeコードをペーストします
画面に表示されれば、設定完了!
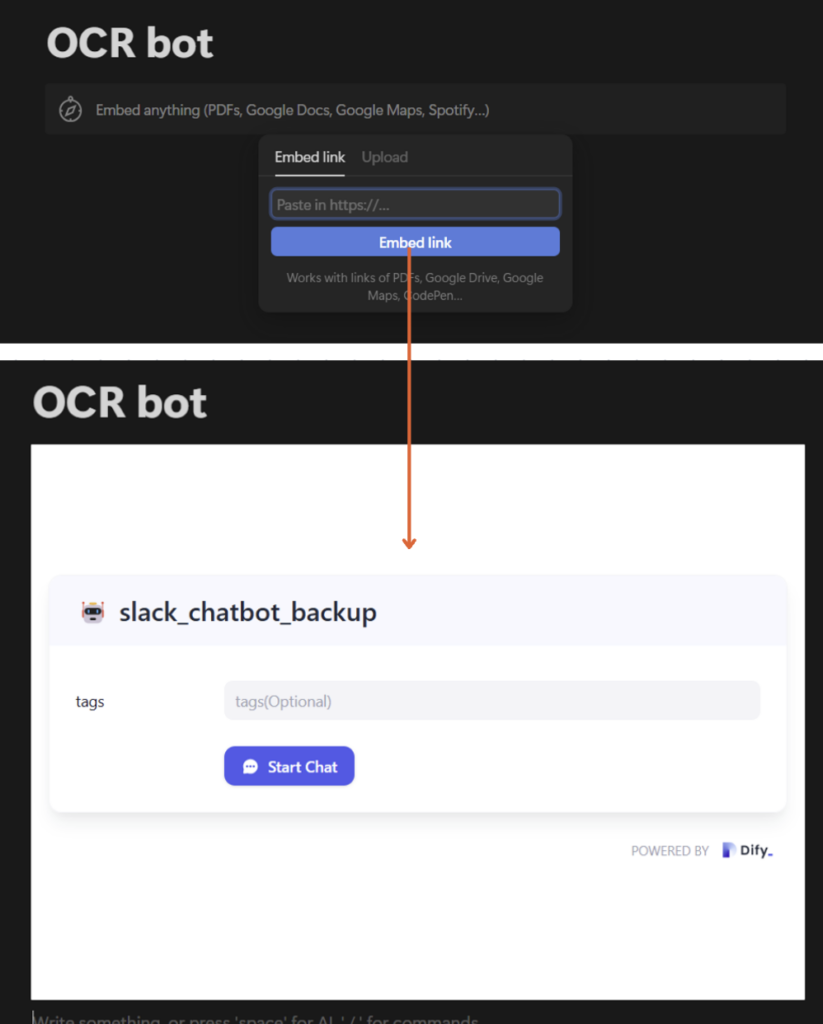
これでワークフローが使用可能になります!
■ ワークフロー設計・構築ガイド
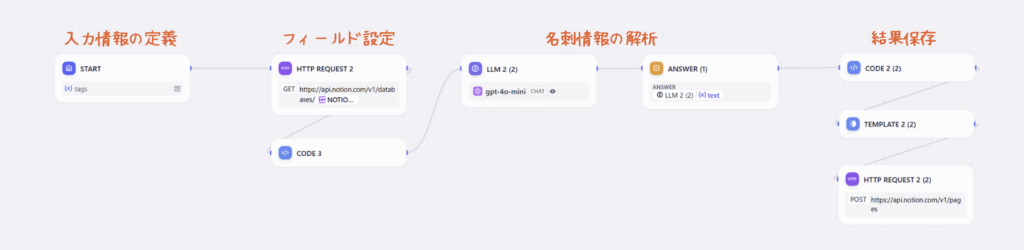
このセクションでは、Difyワークフローの各部分について詳しく説明します。
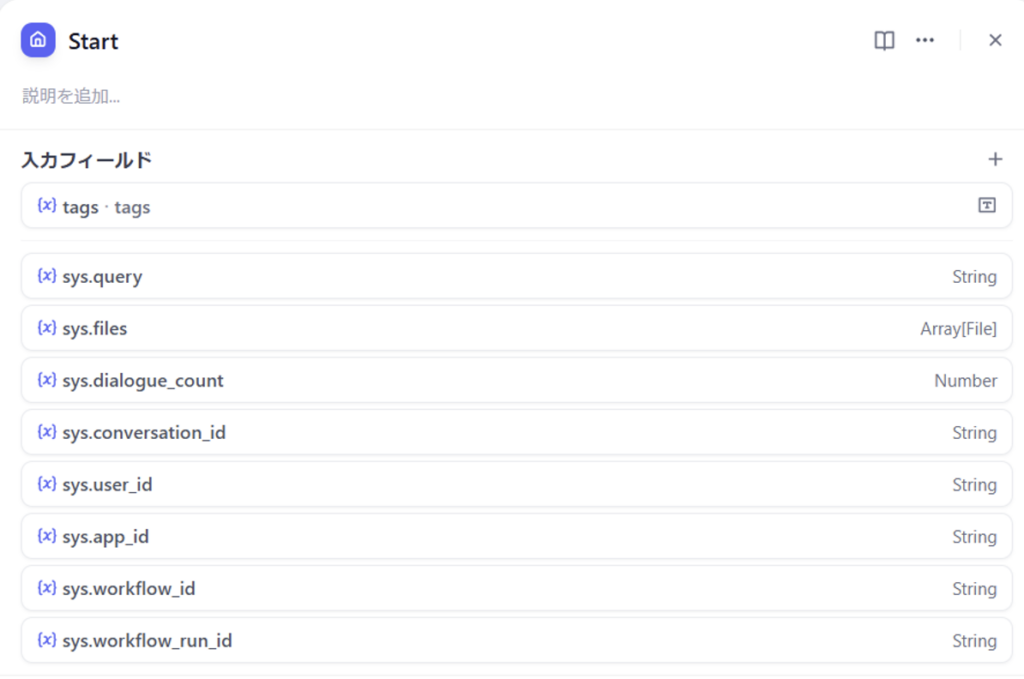
ワークフローの入力には、以下の情報が含まれます:
- タグ:ユーザーが名刺情報に追加したいタグやラベル
① フィールド設定
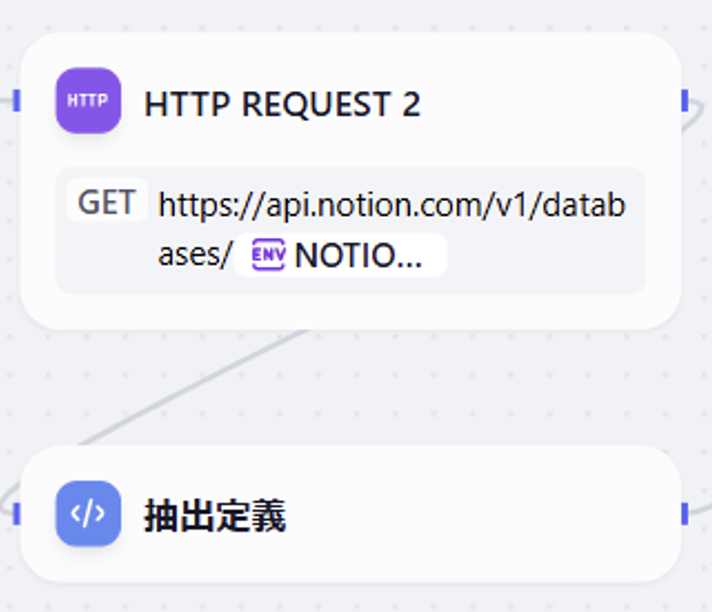
この部分では、Notionで定義されたフィールド情報を取得し、それをLLMに送信します。これにより、入力データが適切に処理され、正確に分類されます。
② 名刺情報の解析
名刺の内容を解析し、Notionで指定されたフィールドに基づいて必要なデータを抽出します。このプロセスでは、プロンプト設計が重要で、精度の高いデータ抽出が可能になります。詳細なプロンプトは、ワークフロー設定で確認できます。
③ 抽出結果の保存
抽出したデータは、Notion APIが要求するJSON形式に変換して、保存します。この変換は「テンプレート」ツールを使って行います。以下はそのテンプレートの例です。
{
"parent": {
"database_id": "{{ NOTION_DB_ID }}"
},
"properties": {
{% for field, value in data.items() %}
"{{ field }}":
{% if attributes.get(field).type == "title" %}
{
"title": [{
"text": {
"content": "{{ value }}"
}
}]
}
{% elif attributes.get(field).type == "email" %}
{
"email": {% if value %}"{{ value }}"{% else %}null{% endif %}
}
{% elif attributes.get(field).type == "url" %}
{
"url": {% if value %}"{{ value }}"{% else %}null{% endif %}
}
{% else %}
{
"rich_text": [{
"text": {
"content": "{{ value }}"
}
}]
}
{% endif %}
{% if not loop.last %},{% endif %}
{% endfor %}
}
}このテンプレートは、テキスト、メール、URLの情報をNotionに送信できるように設計されています。異なる情報形式を扱う場合は、Notion API リファレンス(公式ドキュメント)を参考にして、必要なJSON構造をカスタマイズしてください。
このワークフロー設計により、データは正確に処理され、効率的にNotionに保存されます。
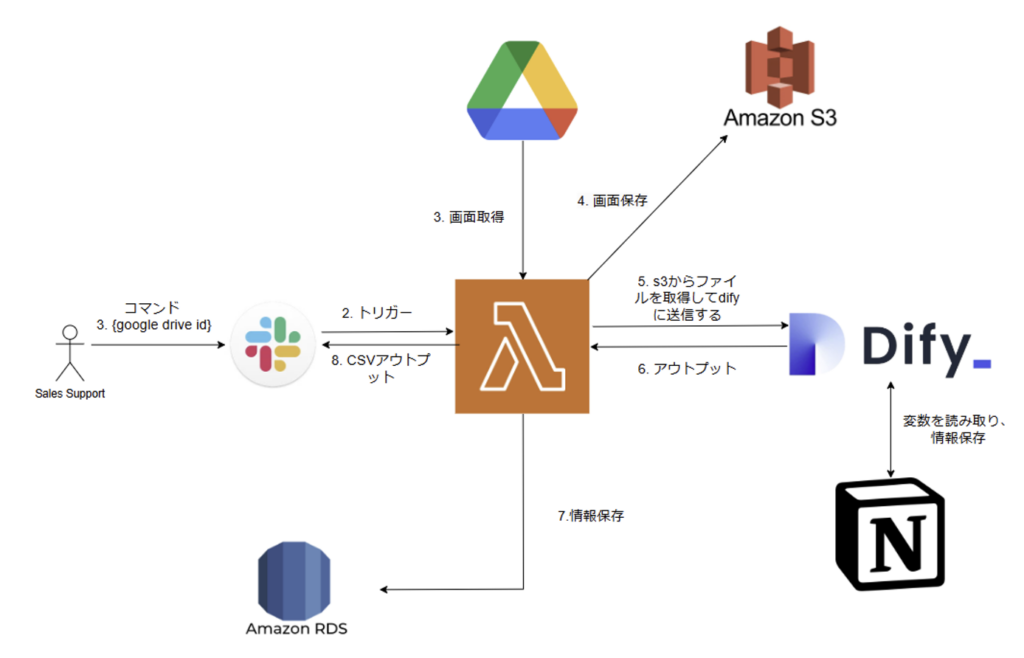
「Dify x Notion x Slack・Google Drive」の組み合わせたフロー
上記では、OCRツールを使って名刺情報を自動で読み取り、記録する方法を説明しました。次に、内部向けバージョンの概要を紹介しますが、出力フォーマット(CSV)やCRMツール、データ形式が各社の業務に合わせて調整が必要だから、特定の設定は公開していません。構築方法に興味がある方は、お気軽にご連絡ください。
内部向けバージョンには技術的な内容が含まれますので、技術に詳しくない方はスキップしても問題ありません。
【補足】
Slackでは一度に最大10枚の画像しかアップロードできない制限があります。この制限を超えるために、Google Driveを利用し効率化します。
機能
① Slackからの画像受信と送信
・Slackに画像がアップロードされると、Lambdaがトリガーされ、指定された処理が実行されます。
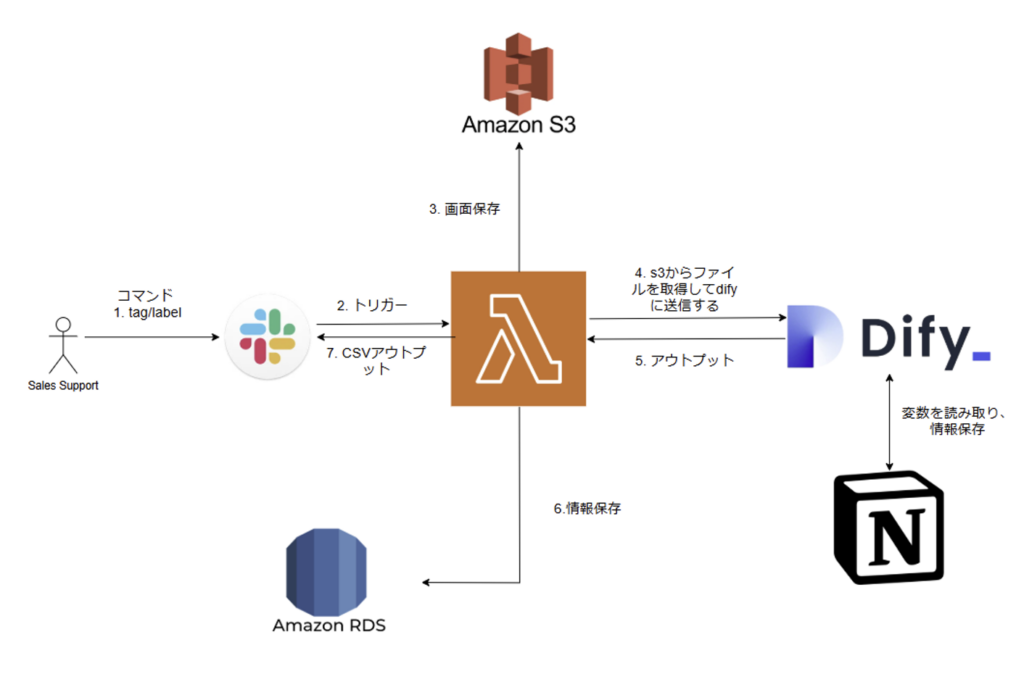
② データのクエリとCSV出力
・RDSから過去のデータをクエリし、結果をCSV形式でSlackに送信します。

③ Google Driveから画像取得と処理
・Google Driveから画像を取得し、Difyで処理後、CSV形式で結果をSlackに返却します。
ツールの準備
⑴ Slackアカウント
概要:Slackはインターフェースとして機能し、ツールの操作を行うため、Slackアカウントが必要です。
⑵ AWSアカウント
概要:SlackとDifyを接続し、画像を自動でアップロードするためにAWS LambdaとAWS S3が必要です。
- AWS Lambda:ユーザーの指示や画像を受け取り、処理してDifyへ転送。
- AWS S3:画像を一時保存し、Difyへ送信。
- AWS RDS PostgreSQL:主なデータ保存用ツール。
⑶ Google Cloud
概要:Google Drive APIはGoogle Cloudを通じて作成され、AWS LambdaがDriveから画像を取得できるようになります。
ツールの詳細設定
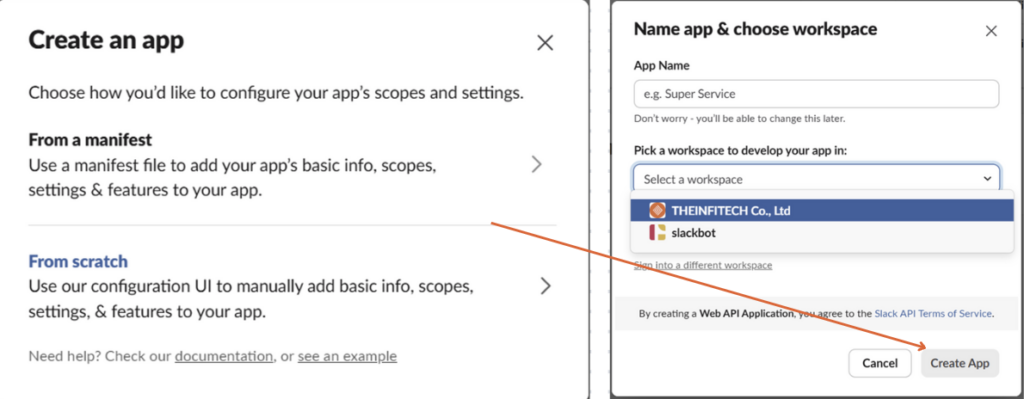
■ Slackアプリの作成
① こちらのリンクにアクセスし、Slackのアプリを作成します
②「Create New App」をクリックし、「From scratch」を選択後、アプリ名とワークスペースを入力して「Create App」をクリック
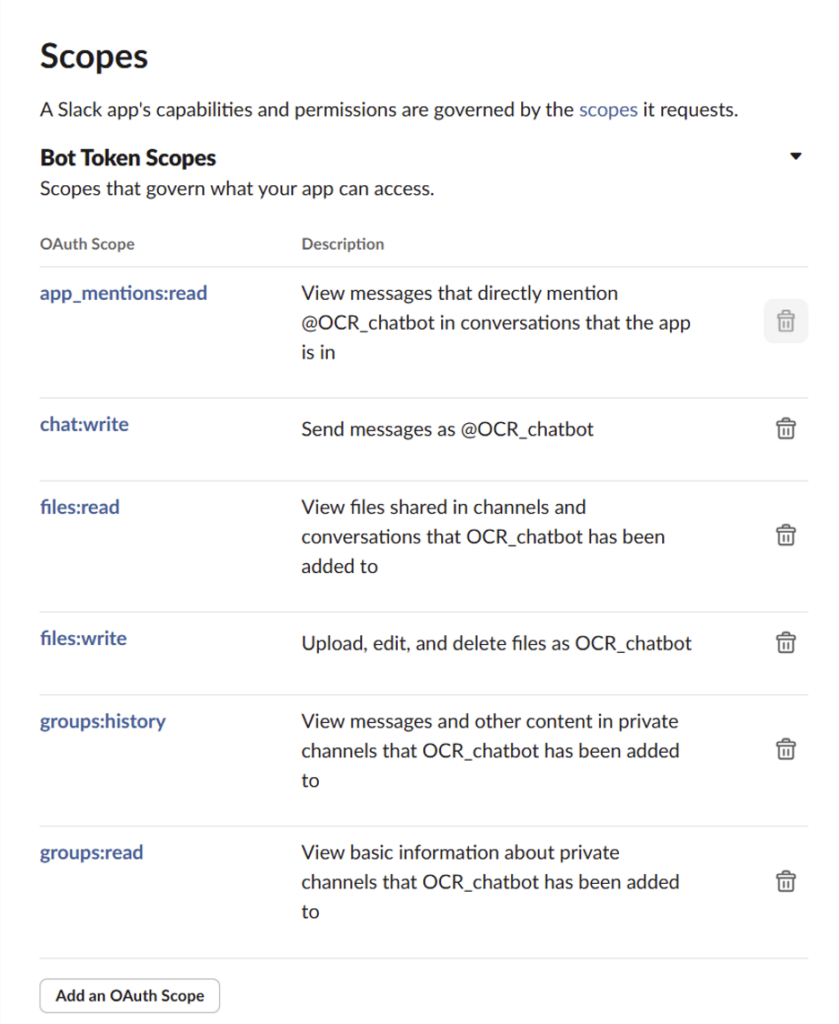
③ 権限の付与
「Features」メニューの「OAuth & Permissions」で、必要な権限を付与します。
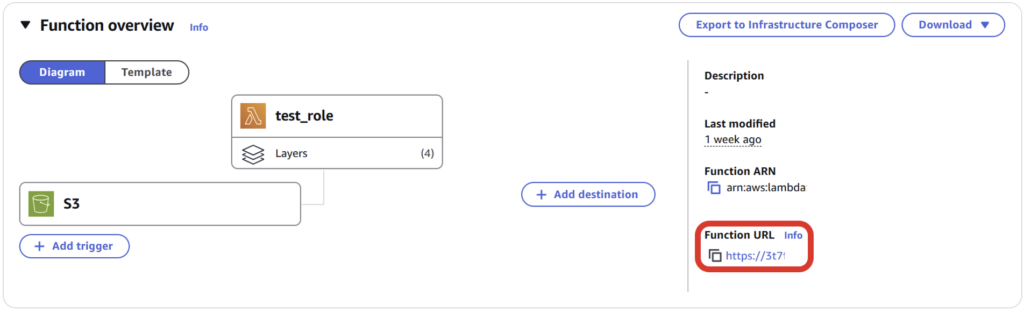
■ Lambda関数URLの作成
① Lambda関数の作成と設定
AWSコンソールでLambda関数を作成し、関数の「設定」から「関数URL」を設定します。
その後、以下のコードをAWS Lambdaにデプロイします。
import json
def lambda_handler(event, context):
body = json.loads(event['body'])
if body.get('type') == 'url_verification':
response = {
'statusCode': 200,
'body': json.dumps({
'challenge': body['challenge']
}),
'headers': {
'Content-Type': 'application/json'
}
}
return response
return {
'statusCode': 400,
'body': json.dumps({'message': 'Invalid request'})
}
Lambda関数のURL(Function URL)をコピーしてください。
② Event Subscriptionsの設定
Slackに戻り、「Event Subscriptions」からイベント設定を行います。
「Request URL」には、先程作成したLambda関数URLを入力します。
「Subscribe to bot events」には、Botにメンションしたときに動作するよう、app_mentionを設定します。
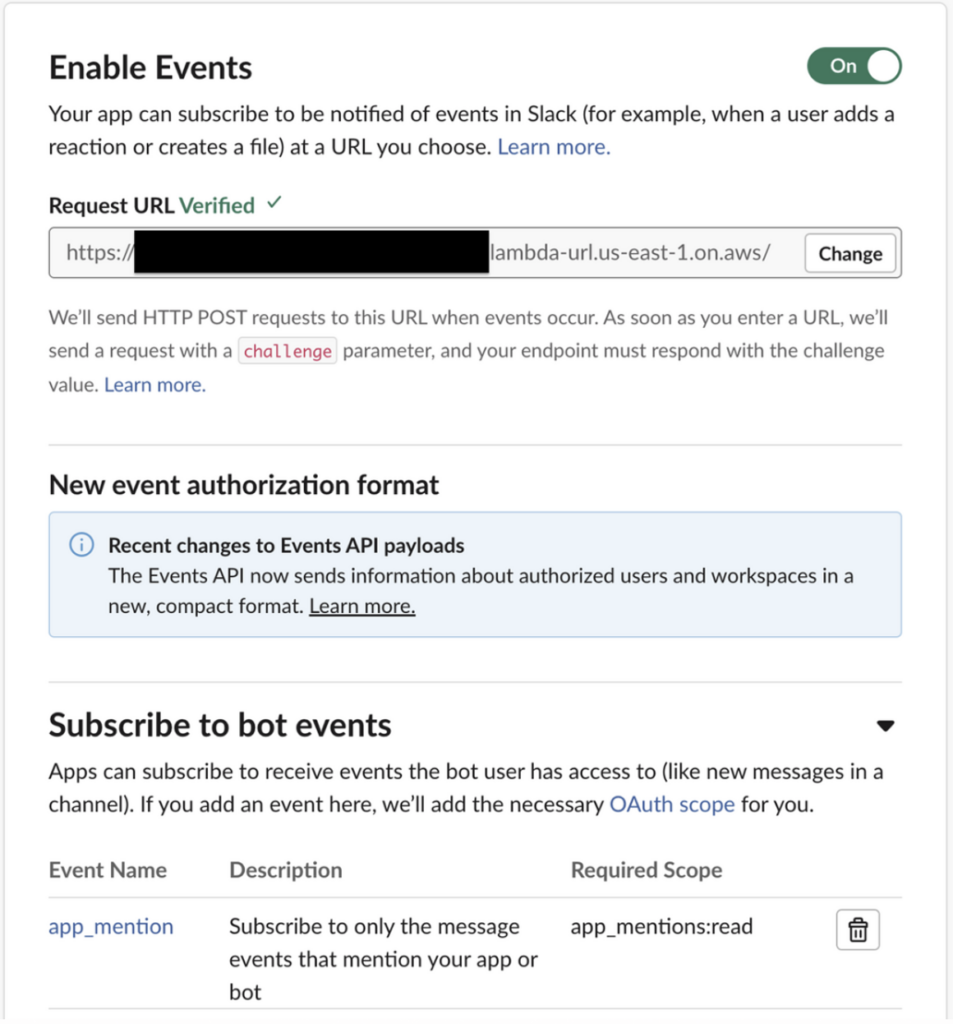
上記設定が完了すれば、SlackとAWSの接続が完了です。
③ アプリのインストールとOAuthトークン取得
最後に「Install App」をクリックしてアプリをインストールし、Bot User OAuth Token(slack_bot_token)を取得します。
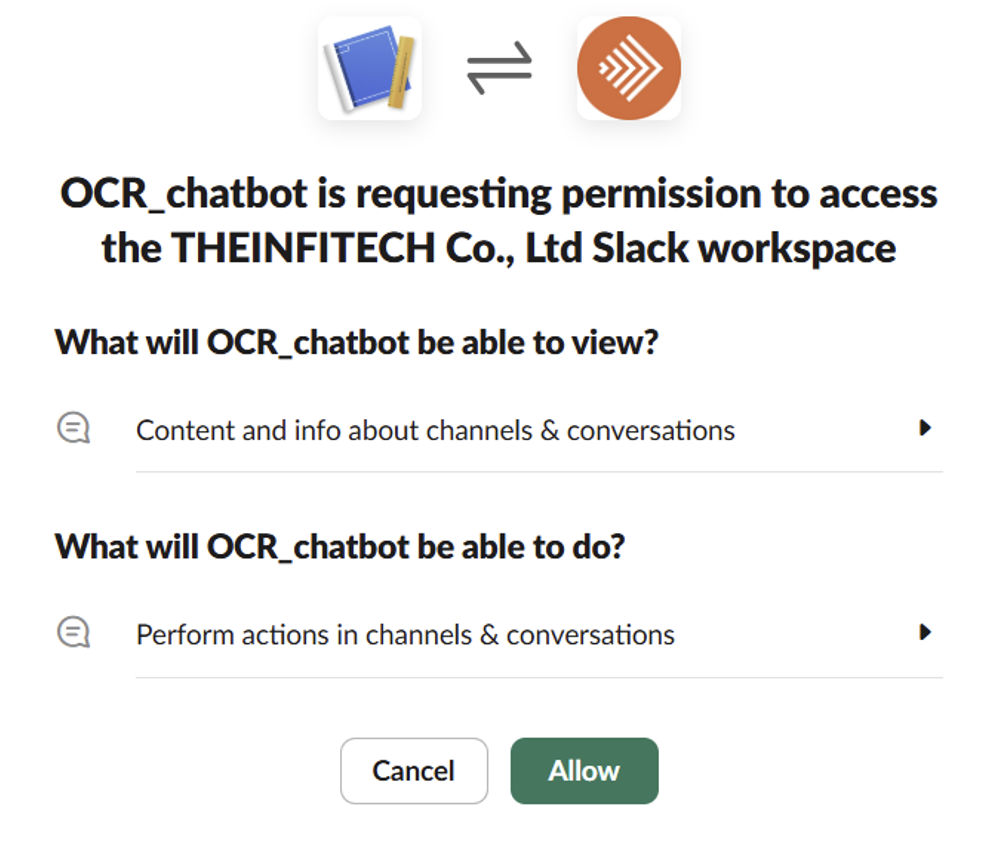
ワークスペースにアップを設定すれば、準備完了です!
■ Dify のAPI の取得
アプリ作成後、『公開する』をクリックして公開し、左の『APIアクセス』からAPIキー(dify_token)を取得します。
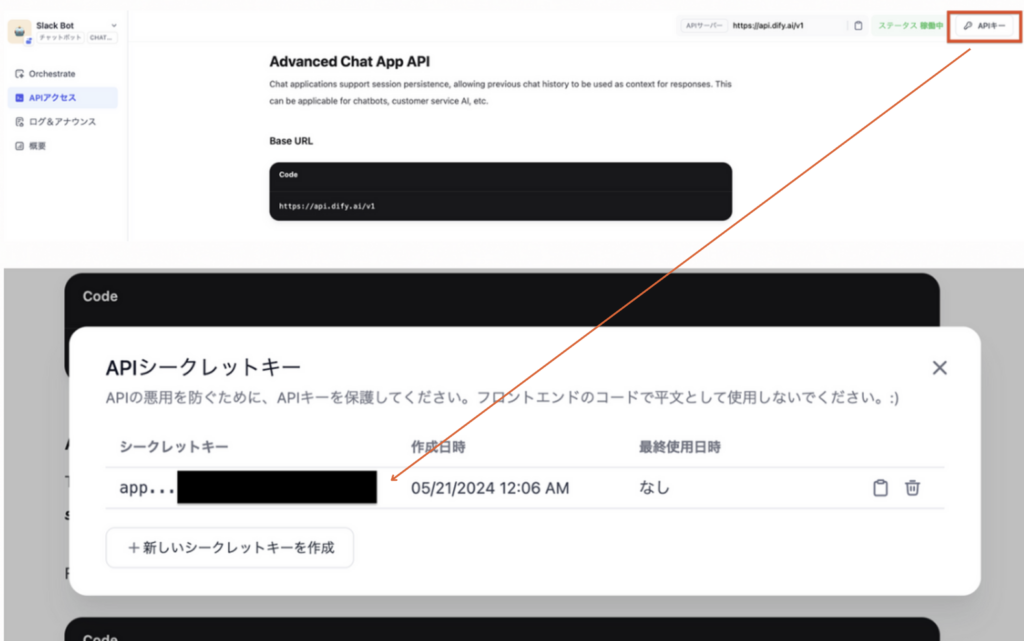
■ Google Cloud の準備
① Google Cloudの新しいプロジェクトを作成します
・Google Cloud Consoleにアクセスし、プロジェクトを選択します。まだプロジェクトがない場合は、「New Project」をクリックして新規作成してください。
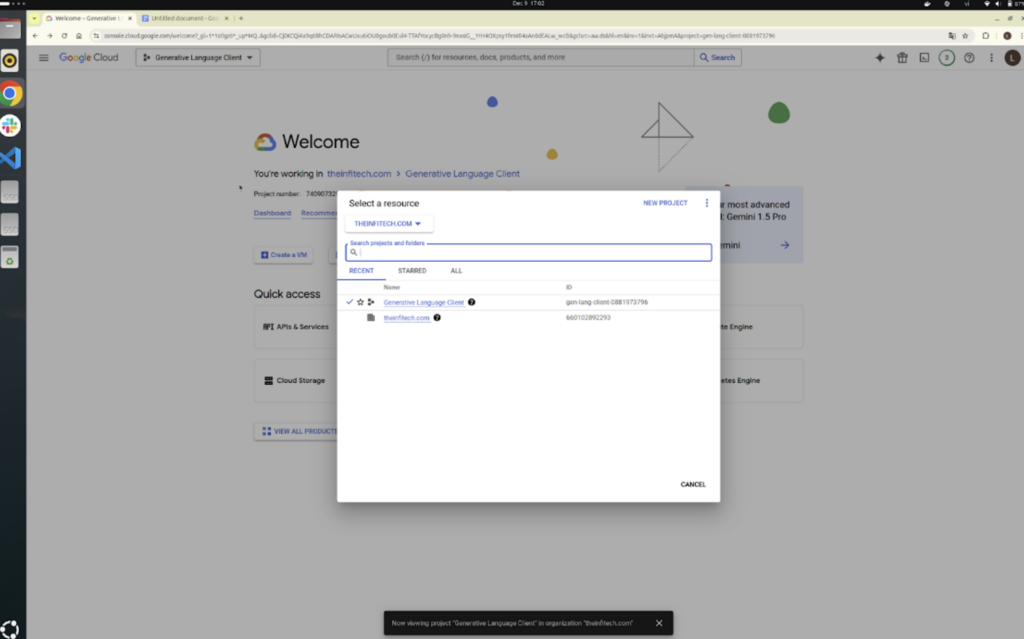
② APIs サービスを有効化に
・「APIs & Services」メニューから「Enable APIs and Services」を選択します

③ Google Drive APIの有効化
・「Google Workspace」セクションで「Google Drive API」を選び、APIを有効化します
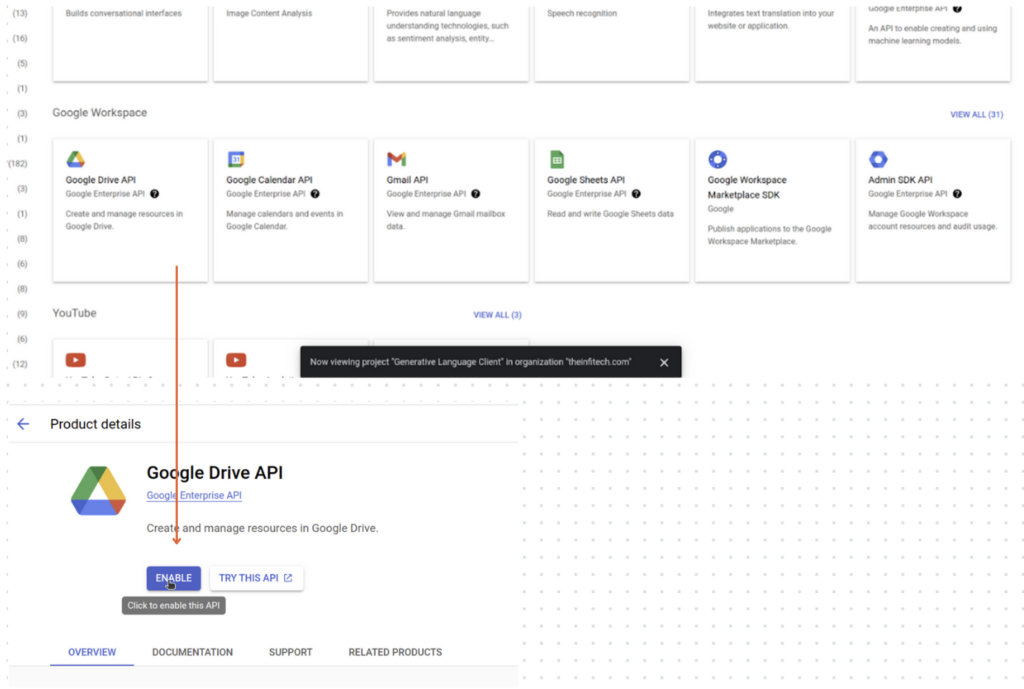
④ API keyの取得
「Credentials」タブで「Create Credentials」→「API key」をクリックし、生成されたAPIキー(drive_token)を保存してください。
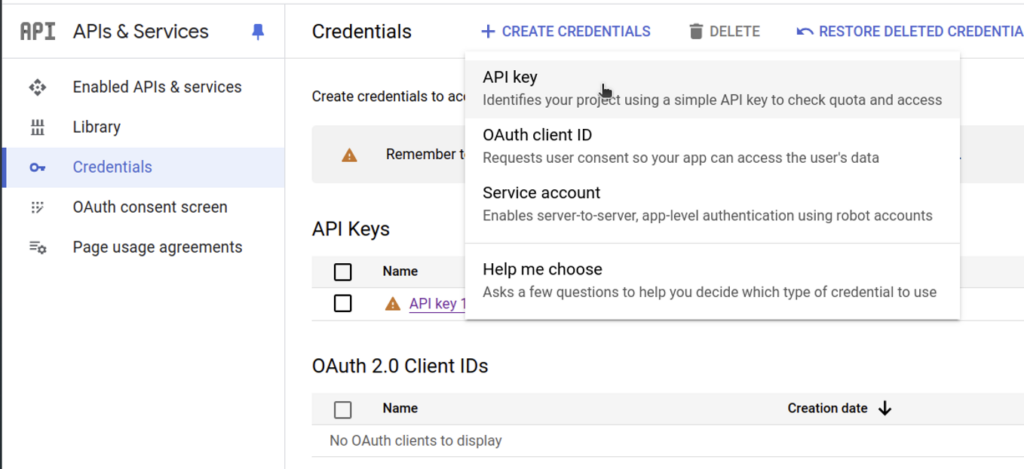
これでGoogle Cloudの準備が完了します。
■ AWS S3とAWS RDS PostgreSQLの準備
AWS S3とRDS PostgreSQLの準備には、以下の情報が必要です:
- bucket_name:S3バケツ名(ファイル保存用)
- db_host:RDS PostgreSQLのデータベースホスト名
- db_username / db_password:データベースへのアクセス用認証情報
また、AWS LambdaにはS3とRDSへの読み書き権限が必要です。この設定で、Lambdaからデータ操作ができるようになります。
■ AWS Lambda関数の作成
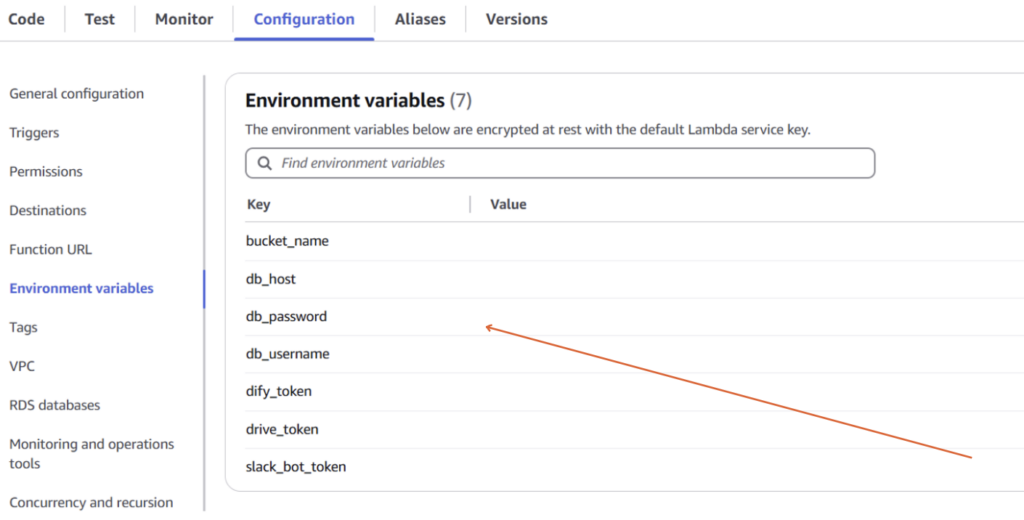
① 情報の準備と設定
・必要な情報をすべて準備したら、AWS Lambdaに戻り、これらの情報を環境変数として設定します。
② コードの実行について
・実行コードの詳細は公開していませんので、興味のある方はお気軽にお問い合わせください。
◇ さっそく試してみよう!
① Slackに名刺の登録
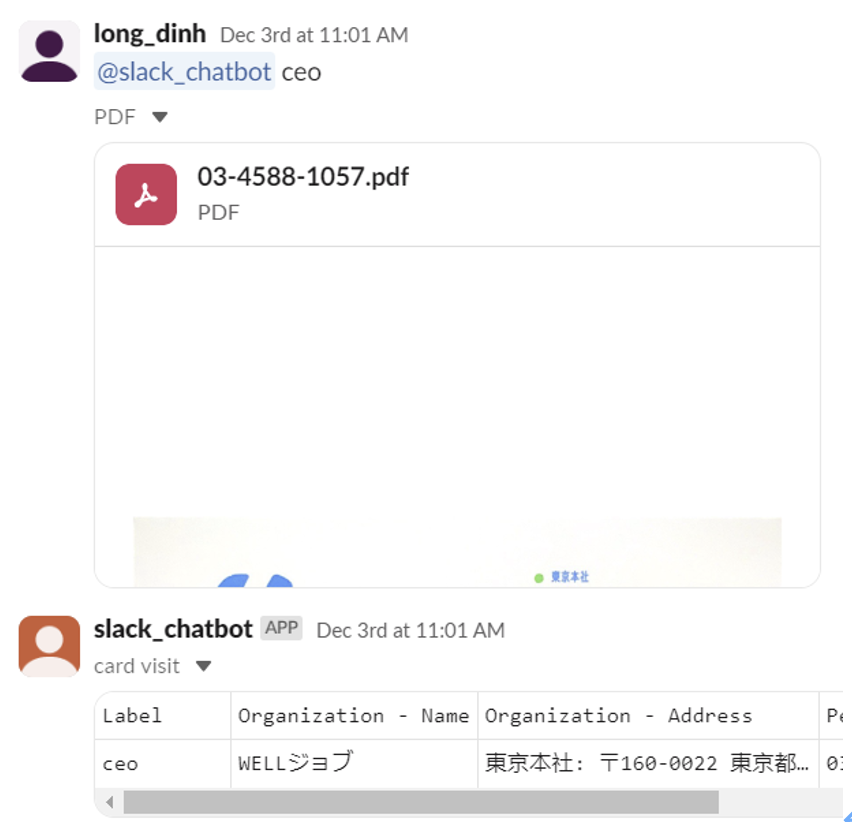
② 決まった時間内でのデータ取得
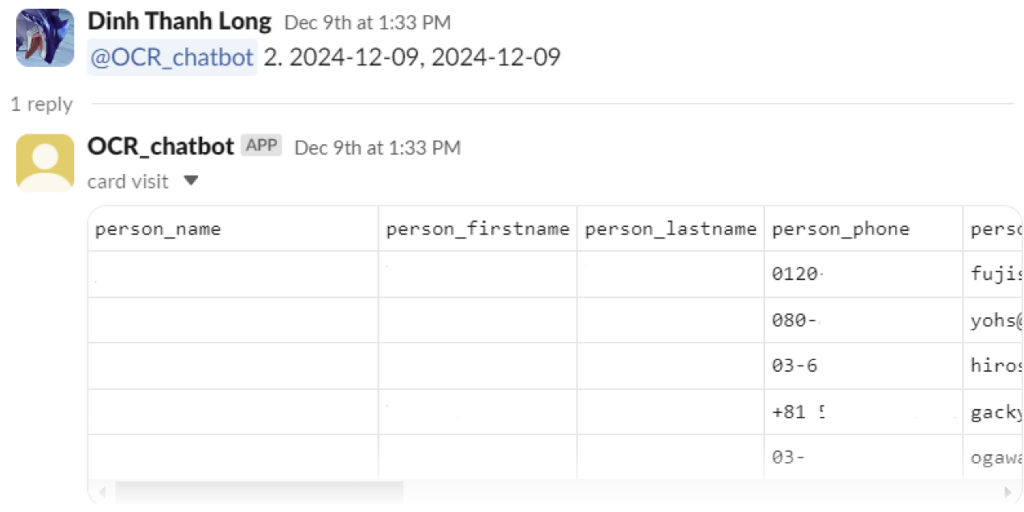
③ Google Driveから画像を取り込み、処理を行う
現在、ツールは社内のGoogle Driveに接続されていますが、フォルダIDの取得権限がないため、デモの実施はできません。ご了承ください。ぜひ、実際にご自身で体験してみてください。
終わり
最後までお読みいただき、ありがとうございます!
今回は、Difyと他ツールを組み合わせた名刺情報管理の自動化ワークフローをご紹介しました。効率的なデータ処理で作業負担を軽減し、成果を最大化できます。
改善点やご意見があれば、ぜひお聞かせください!
共に強力なコンテンツ戦略を築きましょう!今後ともよろしくお願いいたします。
お問い合わせ先
AI/LLM/ビッグデータ/SalesTech/HRTech/PropTechなどの最新情報を入手するには、SNSで当社のCEOをフォローまたは連絡してください
- Twitter: https://x.com/manhnd11
- Linkedin: https://www.linkedin.com/in/manh-theinfitech/
- Facebook: https://www.facebook.com/manhnd11







