Introduction: AI’s Evolution is Unstoppable! The New Potential Demonstrated by Gemini 2.5 In recent years, Generative AI has undergone remarkable evolution, poised to bring significant changes to our workstyles and lives. It’s moving beyond mere text generation, handling diverse information like images, audio, and video, and even acquiring the ability to execute tasks autonomously. At […]

Introduction: What is Firebase Studio? In the modern era where AI has begun to permeate, full-stack development is entering a new phase. While the need to quickly bring ideas to life and incorporate intelligent features is growing, developers have faced numerous challenges such as “the complexity of environment setup,” “technical hurdles in integrating AI models,” […]

In the world of big data, having access to timely and accurate information is crucial. However, with the vast amount of data scattered across the internet, gathering that data is far from simple. This is where data scraping comes into play. In this post, we will explore the challenges and solutions around building a scalable […]

Introduction In the ever-evolving landscape of artificial intelligence, a new player has emerged: Graph RAG. Recently open-sourced by Microsoft, Graph RAG combines the power of knowledge graphs with Retrieval Augmented Generation (RAG), promising to enhance the capabilities of traditional RAG systems. In this blog post, we’ll dive deep into how Graph RAG functions, and experiment […]

Introduction Digital transformation (DX) is growing rapidly, and with it the necessity of classifying massive text sets. Latent Dirichlet Allocation (LDA), a popular approach for locating hidden topics in text data, is one effective way to handle this problem. This article will show you how to use LDA with the AG News dataset, which is […]

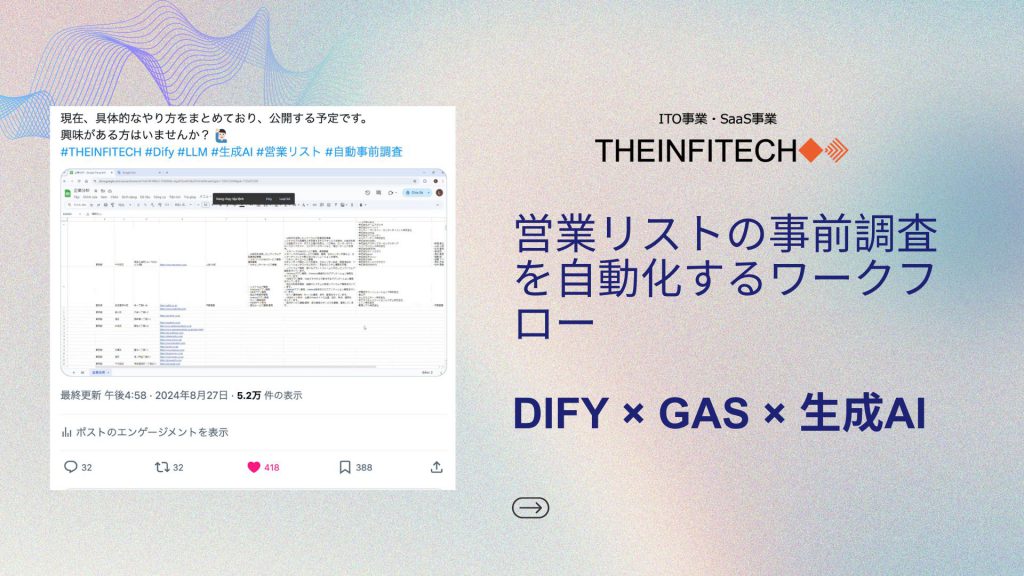
背景 営業活動で、ターゲット企業の事前調査に時間がかかることはありませんか?この課題を解決するために、「Dify x Google App Script x LLM x 検索 x スクレイピング」を活用し、営業リストの事前調査を自動化する方法をPoCしました。 「企業名と所在地」、「企業名と代表取締役社長名」、または「企業名とホームページURL」等を入力するだけで、代表者名や事業内容、取引先情報、役員リスト、SNSアカウント情報などを数分で取得できるため、調査にかかる時間を大幅に短縮し、営業活動の効率化を実現します。 さらに、Difyと生成AIを活用すれば、個別にカスタマイズされたツールを無料で作成・利用でき、コストを抑えつつ、営業の効果を最大化できます。 具体的な方法は現在まとめており、近日公開予定です。興味のある方はお楽しみに! フローの概要 下記は、DifyとGASと生成AIを活用して、企業調査を自動で行うフローについて解説します。 Google Sheetに調査したい企業をインプットする まず、Google Sheetの特定の列に調査したい企業情報を入力する必要です。それをインプットとして、弊社が作ったフローでスクレイピング、検索、情報検索等を行います。 今回は、下記の4つのケースを対応しております: Google Sheet上に結果出力 各企業ごとに、下記の項目の情報を検索・抽出して、生成AIでまとめたものを、結果はシート上に事情を該当な列に入力されます: フローを行うため、準備必要なもの まずは準備として、以下のものを用意してください。 クラウド版Difyのアカウント SerpDev APIキー ※SerpDevは1つのアカウントに対して、2500回まで無料でAPIを呼び出せます。 LLM APIキー Firecrawl APIキー ※Firecrawlは1つのアカウントに対して、500ページまで無料でScrapeできます。 スプレッドシートとGAS Dify ワークフロー この準備を完了することで、ワークフローの各ステップをスムーズに進めることができます。 フローの解説 実装に入る前に、Difyのワークフローについて説明いたします。このフローは「企業情報検索・抽出」と「代表者のSNSアカウント情報検索・抽出」、大きく2つの部分に分かれています。 企業情報検索・探索 ワークフローの上段は、企業情報を探索するためのもので、3つの検索ケースがあります。各ケースについて詳述します。 「企業名」と「本社住所」だけ含まれている このケースでは、ユーザーが「企業名」と「本社住所」のみを入力した場合に、企業情報の探索プロセスが適用されます。プロセスは、2回の検索と情報統合のステップで構成されています。 手順1: 初回の企業情報検索 最初の検索では、企業名と「情報概要」というキーワードを組み合わせてGoogle検索用のクエリ(q値)を作成します。次に、Google検索を実行し、最初の3件の検索結果を取得します。これらのURLに対して、Jina Readerを使用してウェブサイトの内容を抽出します。 その後、LLM(大規模言語モデル)を使用して各ウェブページから企業情報を抽出し、取得した3件の情報を統合して一貫した内容にまとめます。 <補足情報> 手順2: 2回目の企業情報検索 2回目の検索も同様のプロセスで進行しますが、クエリの構成が異なります。ここでは、「会社名」+「住所」+「会社概要」というキーワードを組み合わせたクエリを使用します。再び、Google検索を実行し、上位3件の結果からウェブサイトの内容をJina […]